kube-proxy is a key component of any Kubernetes deployment. Its role is to load-balance traffic that is destined for services (via cluster IPs and node ports) to the correct backend pods. Kube-proxy can run in one of three modes, each implemented with different data plane technologies: userspace, iptables, or IPVS.
The userspace mode is very old, slow, and definitely not recommended! But how should you weigh up whether to go with iptables or IPVS mode? In this article, we’ll compare the two, measure how they perform in the context of a real microservice, and explain when you might want to choose one versus the other.
First, we’ll start with a bit of background on the two modes, then dive into the testing and results below…
Background: iptables proxy mode
iptables is a Linux kernel feature that was designed to be an efficient firewall with sufficient flexibility to handle a wide variety of common packet manipulation and filtering needs. It allows flexible sequences of rules to be attached to various hooks in the kernel’s packet processing pipeline. In iptables mode, kube-proxy attaches rules to the “NAT pre-routing” hook to implement its NAT and load balancing functions. This works, it’s simple, it uses a mature kernel feature, and, it “plays nice” with other programs that also work with iptables for filtering (such as Calico!).
However, the way kube-proxy programs the iptables rules means that it is nominally an O(n) style algorithm, where n grows roughly in proportion to your cluster size (or more precisely the number of services and number of backend pods behind each service).
Background: IPVS proxy mode
IPVS is a Linux kernel feature that is specifically designed for load balancing. In IPVS mode, kube-proxy programs the IPVS load balancer instead of using iptables. This works, it also uses a mature kernel feature and IPVS is designed for load balancing lots of services; it has an optimized API and an optimized look-up routine rather than a list of sequential rules.
The result is that kube-proxy’s connection processing in IPVS mode has a nominal computational complexity of O(1). In other words, in most scenarios, its connection processing performance will stay constant independent of your cluster size.
In addition, as a dedicated load balancer, IPVS boasts multiple different scheduling algorithms such as round-robin, shortest-expected-delay, least connections, and various hashing approaches. In contrast, kube-proxy in iptables uses a randomized equal cost selection algorithm.
One potential downside of IPVS is that packets that are handled by IPVS take a very different path through the iptables filter hooks than packets under normal circumstances. If you plan to use IPVS with other programs that use iptables then you will need to research whether they will behave as expected together. (Fear not though, Calico has been compatible with IPVS kube-proxy since way back when!)
Performance Comparison
OK, so nominally kube-proxy’s connection processing in iptables mode is O(n) and in IPVS mode is O(1). But what does this translate to in reality in the context of microservices doing real microservice kinds of things?
In most scenarios there are two key attributes you will likely care about when it comes to the performance of kube-proxy in the context of your application and microservices:
- Impact on round-trip response times. When one microservice makes an API call to another microservice, how long does it take on average for the first microservice to send the request to and receive the response back from the second microservice?
- Impact on total CPU usage. What is the total CPU usage of a host when running your microservices, including userspace and kernel/system usage, across all the processes that are needed to support your microservices including kube-proxy?
To illustrate this we ran a “client” microservice pod on a dedicated node generating 1,000 requests per second to a Kubernetes service backed by 10 “server” microservice pods running on other nodes in the cluster. We then measured performance on the client node in both iptables and IPVS mode with various numbers of Kubernetes services with each service being backed by 10 pods, up to a maximum of 10,000 services (with 100,000 service backends). For the microservices, we used a simple test tool written in golang as our client microservice and used standard NGINX for the backend pods of the server microservice.
Round-Trip Response Times
When considering round-trip response time it’s important to understand the difference between connections and requests. Typically most microservices will use persistent or “keepalive” connections, meaning that each connection is reused across multiple requests, rather than requiring a new connection per request. This is important because most new connections require a three-way TCP-handshake across the network (which takes time), more processing within the Linux networking stack (which takes a bit more time and CPU).
To illustrate these differences we tested with and without keepalive connections. For the keepalive connections, we used NGINX’s default configuration, which keeps each connection alive for re-use for up to 100 requests. See the graph below and note that the lower the response time the better.
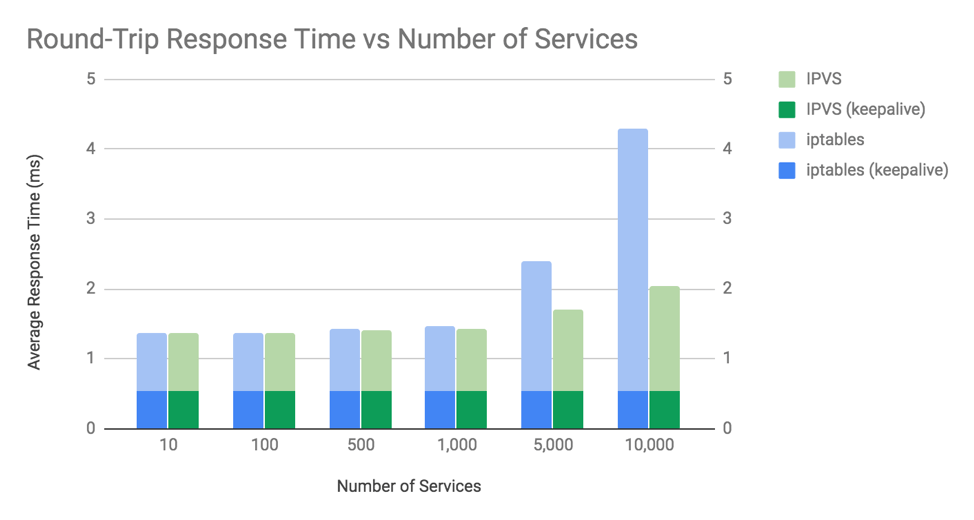
The chart shows two key things:
- The difference in average round-trip response times between iptables and IPVS is trivially insignificant until you get beyond 1,000 services (10,000 backend pods).
- The difference in average round-trip response times is only discernible when not using keepalive connections. i.e. when using a new connection for every request.
For both iptables and IPVS mode, the response time overhead for kube-proxy is associated with establishing connections, not the number of packets or requests you send on those connections. This is because Linux uses connection tracking (conntrack) that is able to match packets against existing connections very efficiently. If a packet is matched in conntrack then it doesn’t need to go through kube-proxy’s iptables or IPVS rules to work out what to do with it. Linux conntrack is your friend! (Almost all of the time…. look out for our next blog post “When Linux conntrack is not your friend”!)
It’s worth noting that for the “server” microservice in this example we used NGINX pods serving up a small static response body. Many microservices need to do far more work than this which would result in correspondingly higher response times, meaning the delta for kube-proxy processing would be a smaller percentage of the response time compared to this chart.
There’s one final oddity to explain: why do non-keepalive response times get slower for IPVS at 10,000 services if the processing of new connections in IPVS is O(1) complexity? We would need to do a lot more digging to really get to the bottom of this, but one factor that contributes is that the system as a whole gets slower due to increased CPU usage on the host. This brings us nicely on to the next topic.
Total CPU
To illustrate the total CPU usage the chart below focuses on the worst case scenario of not using persistent/keepalive connections in which the kube-proxy connection processing overhead has the biggest impact.
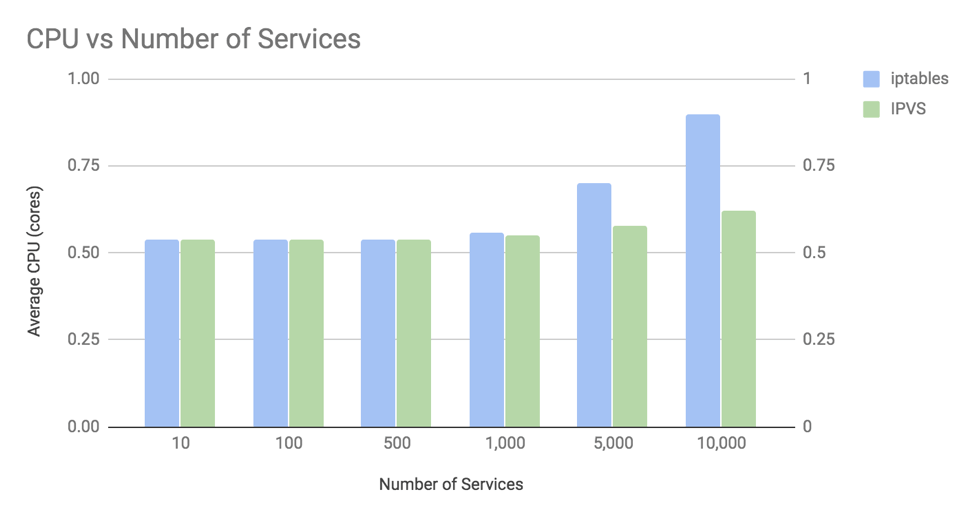
The chart shows two key things:
- The difference in CPU usage between iptables and IPVS is relatively insignificant until you get beyond 1,000 services (with 10,000 backend pods).
- At 10,000 services (with 100,000 backend pods), the increase in CPU with iptables is ~35% of a core, and with IPVS is ~8% of a core.
There are two main contributors that influence this CPU usage pattern.
The first contributor is that by default kube-proxy reprograms the kernel with all services at 30-second intervals. This explains why IPVS mode has a slight increase in CPU even though IPVS’s processing of new connections is nominally O(1) complexity. In addition, the API to reprogram iptables in older kernel versions was much slower than it is today. So if you are using an older kernel with kube-proxy in iptables mode you would see even higher CPU growth than this chart.
The second contributor is the time it takes for kube-proxy’s use of iptables or IPVS to process new connections. For iptables, this is nominally O(n). At a large number of services, this contributes significantly to the CPU usage. For example, at 10,000 services (with 100,000 backend pods) iptables is executing ~20,000 rules for every new connection. Remember though that in this chart we are showing the worst case scenario of microservices that use a new connection for every request. If we had used NGINX’s default keepalive of 100 requests per connection then kube-proxy’s iptables rules are executed 100 times less often, greatly reducing bringing the likely CPU impact of using iptables rather than IPVS down to something closer to 2% of a core.
It’s worth noting that the “client” microservice used in this example simply discards every response it receives from the “server” microservice. A real microservice would need to do far more work than this, which would increase the base CPU usage in this chart, but not change the absolute increase in CPU associated with the number of services.
Conclusions
At scales significantly beyond 1,000 services, kube-proxy’s IPVS mode can offer some nice performance improvements. Your mileage may vary, but as a general guide, for microservices that use persistent “keepalive” style connections, running on a modern kernel, the benefits will likely be relatively modest. For microservices that don’t use persistent connections, or when running on older kernels, then switching to kube-proxy to IPVS mode will likely be a good win.
Independent of performance considerations, you should also consider using IPVS mode if you have a need for more sophisticated load balancing scheduling algorithms than kube-proxy’s iptables mode random load balancing.
If you aren’t sure whether IPVS will be a win for you then stick with kube-proxy in iptables mode. It’s had a ton more in-production hardening, and while it isn’t perfect, you could argue it is the default for a reason.
Afterword: Comparing kube-proxy and Calico’s use of iptables
In this article, we’ve seen how kube-proxy’s use of iptables can lead to performance impacts at very high scales. I’m sometimes asked why Calico doesn’t have the same challenges. The answer is that Calico’s use of iptables is significantly different than kube-proxy’s. Kube-proxy uses a very long chain of rules that grows roughly in proportion to cluster size, whereas Calico uses very short optimized chains of rules and makes extensive use of ipsets, which have O(1) lookup independent of their size.
To put this in perspective, the following chart shows the average number of iptables rules executed per connection by kube-proxy vs Calico assuming that nodes in the cluster host an average of 30 pods and each pod in the cluster has an average of 3 network policies that apply to it.
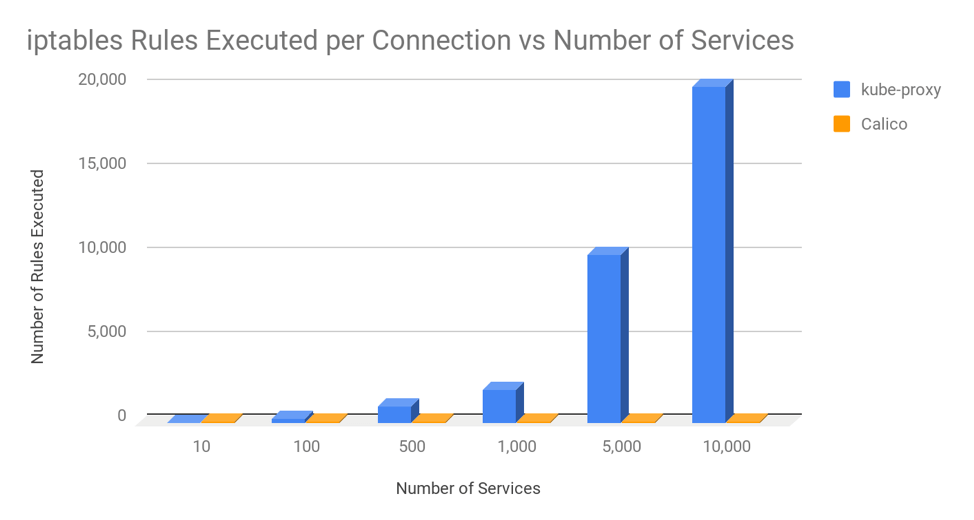
Even when running in a fully scaled out cluster with 10,000 services and 100,000 backend pods, Calico only executes roughly the same number of iptables rules per connection as kube-proxy executes at 20 services with 200 backend pods. In other words, Calico’s use of iptables scales!
————————————————-
Free Online Training
Access Live and On-Demand Kubernetes Training
Calico Enterprise – Free Trial
Network Security, Monitoring, and Troubleshooting
for Microservices Running on Kubernetes
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!


