Today the Calico team merged a new dataplane option to Calico, based on eBPF, the Linux kernel’s embedded virtual machine. This exciting new dataplane will be included as a Tech Preview capability in the next version of Calico, v3.13.
If you aren’t already familiar with the concept of eBPF, it allows you to write mini programs that can be attached to various low-level hooks in the Linux kernel, for a wide variety of uses including networking, security, and tracing. You’ll see a lot of non-networking projects leveraging eBPF, but for Calico our focus is obviously on networking, and in particular, pushing the networking capabilities of the latest Linux kernel’s to the limit while maintaining Calico’s reputation for simplicity, reliability and scalability.
So how does the new dataplane compare to Calico’s standard Linux networking dataplane?
- It scales to higher throughput.
- It uses less CPU per GBit.
- It has native support for Kubernetes services (without needing kube-proxy) that:
-
- Reduces first packet latency for packets to services.
- Preserves external client source IP addresses all the way to the pod.
- Supports DSR (Direct Server Return) for more efficient service routing.
- Uses less CPU than kube-proxy to keep the dataplane in sync.
-
I know what you’re thinking, show me some performance charts and then tell me what you meant by “Tech Preview”…
Performance test environment
For our performance testing we used physical servers running Ubuntu 19.10, connected across a low-latency 40Gbit network. The 40Gbit network allows us to run particularly network intensive workloads, which is where you’ll normally see the most significant benefits compared to standard Linux networking.
Pod-to-pod throughput and CPU
We used qperf to measure throughput between a pair of pods running on different nodes. Since much of the networking overhead is per-packet, we tested with both 1440 byte MTU and 8940 byte MTU (where the MTU is the maximum packet size; 1500 is realistic for internet traffic; 9000 within some data centers; and we reduced both by 60 to be conservative in case you are running on top of an overlay network). We measured both throughput and CPU usage.
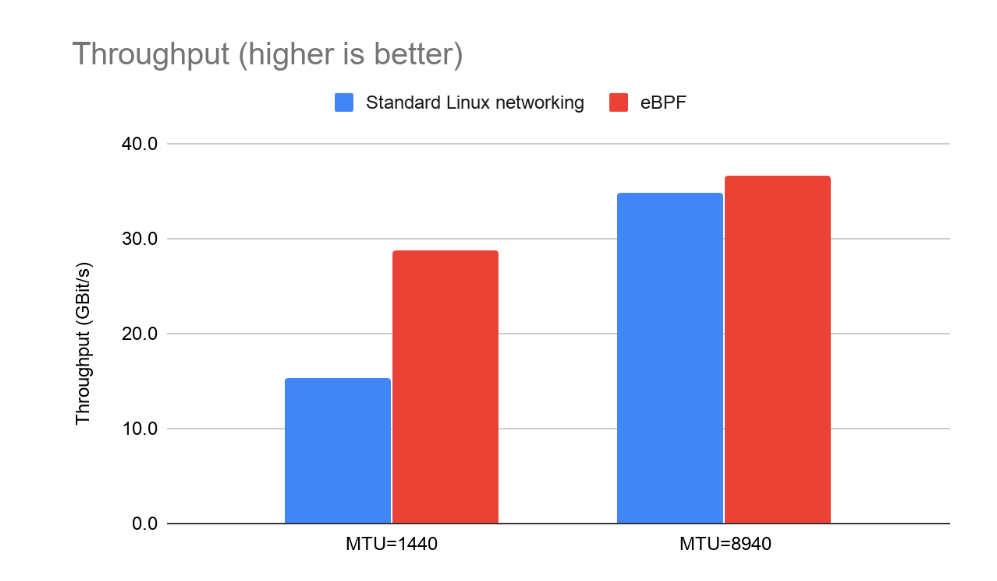
As you can see, with a 8940 MTU both options come close to saturating the 40Gbit link. At the smaller packet size, we see a gap in throughput open up.
Note that qperf generally limits itself to a single core, which makes it a great tool for seeing how much traffic can be pushed by an application with a limited amount of CPU. But it’s important not to misinterpret this data as the throughput limit for the node, rather than for a single instance of qperf. With either dataplane you could saturate the 40Gbit link if you threw more CPU at a multi-threaded application or ran more pod instances.
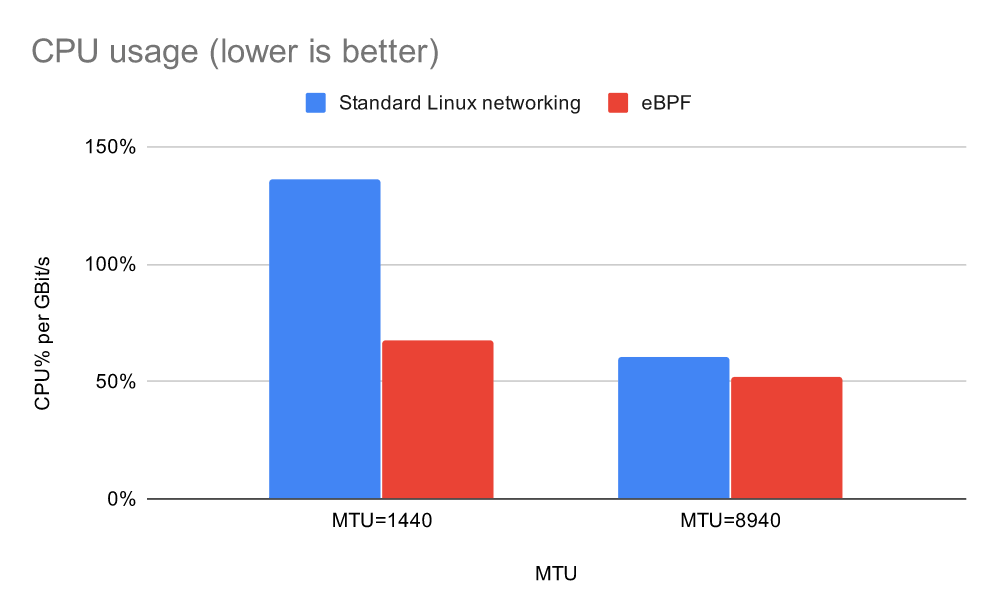
Normalising the CPU usage per GBit, the eBPF dataplane uses significantly less CPU per GBit than the standard Linux networking dataplane, with the win being biggest at small packet sizes.
Improving on kube-proxy
When we first embarked on our eBPF journey, we hadn’t planned to replace kube-proxy. As a general philosophy, maintaining compatibility with upstream Kubernetes components when possible is usually beneficial to the community. And despite some of the popular hype, kube-proxy’s use of iptables for load balancing works great for most users. It isn’t until you start to scale to thousands of services that most users would see any significant performance impact, and for those who are running thousands of services, kube-proxy’s IPVS mode solves these performance issues.
However, as we progressed, we found that the optimum eBPF design for Calico’s features wouldn’t be able to work with the existing kube-proxy without introducing significant complexity and reducing overall performance.
Once we were nudged towards replacing kube-proxy, we decided to see how we could improve on the upstream implementation by natively handling Kubernetes services within the Calico dataplane.
First packet latency
For both kube-proxy and our implementation, only the first packet in a new flow pays the price to figure out which pod the flow will be load balanced to. (Subsequent packets take a conntrack fast path, which is independent of the number of services you are running.) To measure the impact of first packet latency, we used curl with verbose debug output turned on to measure the “connect time” to an nginx pod. This is the time to do the TCP handshake exchange (one packet in each direction).
We varied the number of services and ran the test with kube-proxy both in IPVS and iptables mode and with our eBPF dataplane.
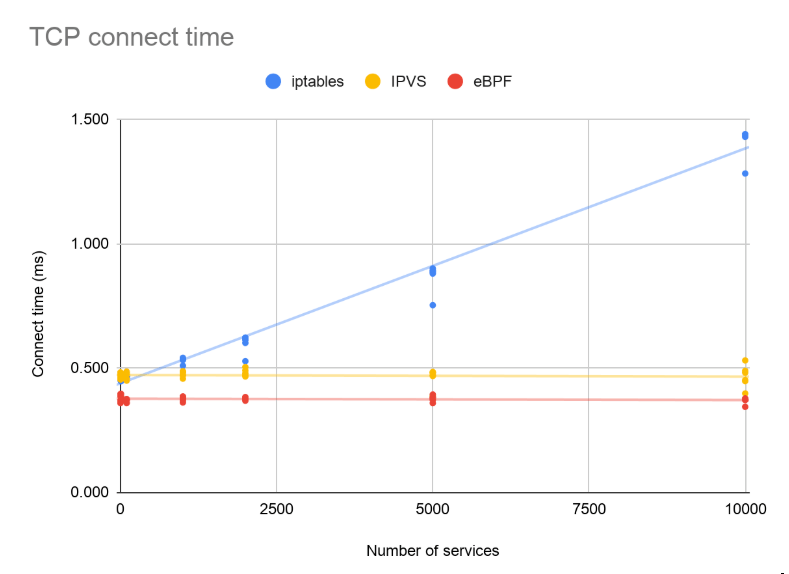
In iptables mode, kube-proxy’s implementation uses a list of rules that grows with the number of services. Hence, its latency gets worse as the number of services increases. Both IPVS mode and our implementation use an efficient map lookup instead, resulting in a flat performance curve as the number of services increases.
It’s important to put these numbers into context. While IPVS and our eBPF mode are faster than the alternative, this is only the first packet. If your workload is re-using connections (as is typically the case for gRPC or REST APIs), or transfering a 1MB file, then the half-millisecond saving from this change won’t be noticeable. On the other hand, if your workload involves thousands of short-lived, latency-sensitive connections, you’ll see a real gain. (For a more complete read on this topic that explores the real-world performance impacts of kube-proxy iptables vs IPVS modes, check out this blog.
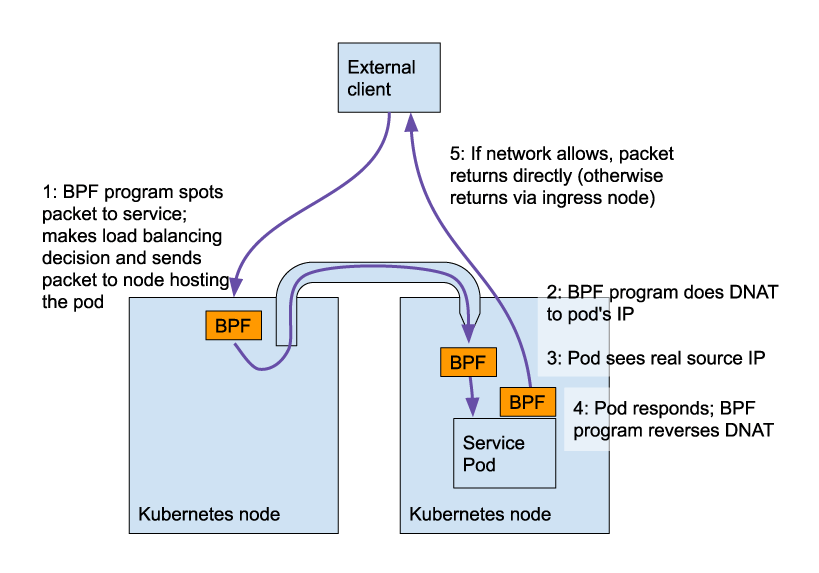
Preserving external source IPs, and Direct Server Return
One of the pain points of mixing network policies with Kubernetes services is that the source IP of an external client gets lost when the traffic is redirected by kube-proxy upon entering the cluster.
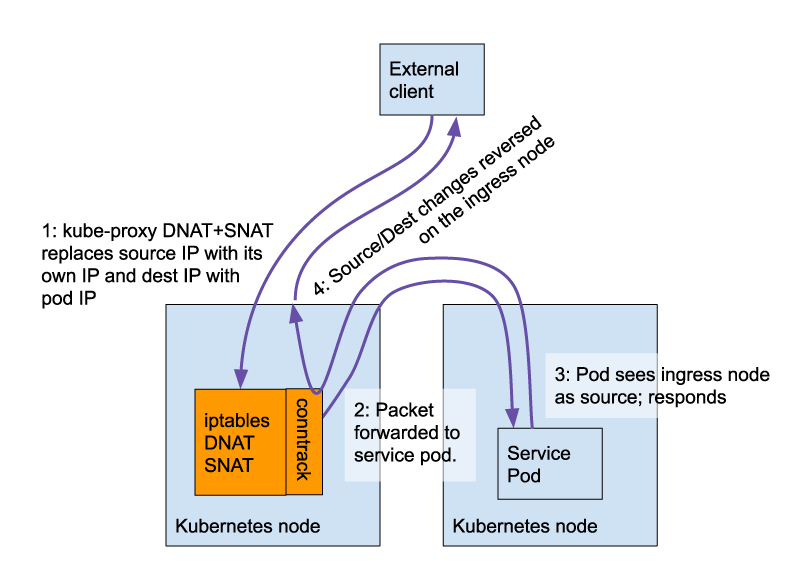
This means that ingress network policy and the pod itself both see the packet’s source IP as the ingress node rather than the real, external client. In addition, the return traffic needs to travel back via the original ingress node so it can reverse the DNAT+SNAT and return the traffic to the original client source IP.
(The exception is for Kubernetes services with externalTrafficPolicy:Local, which load balance to local pods only, without changing the source IP.)
With our eBPF implementation we can preserve the original source IP and can optionally perform Direct Server Return (DSR). i.e. the return traffic can take the optimal path without needing to loop back through the original ingress node.
How does our implementation perform? The graph below shows the connect and total time as reported by curl for accessing an nginx service (serving the standard nginx hello-world page) over a node port, where the backing pod is on a different node to the ingress node. To give a realistic baseline, there were 1,000 other services configured for this test.
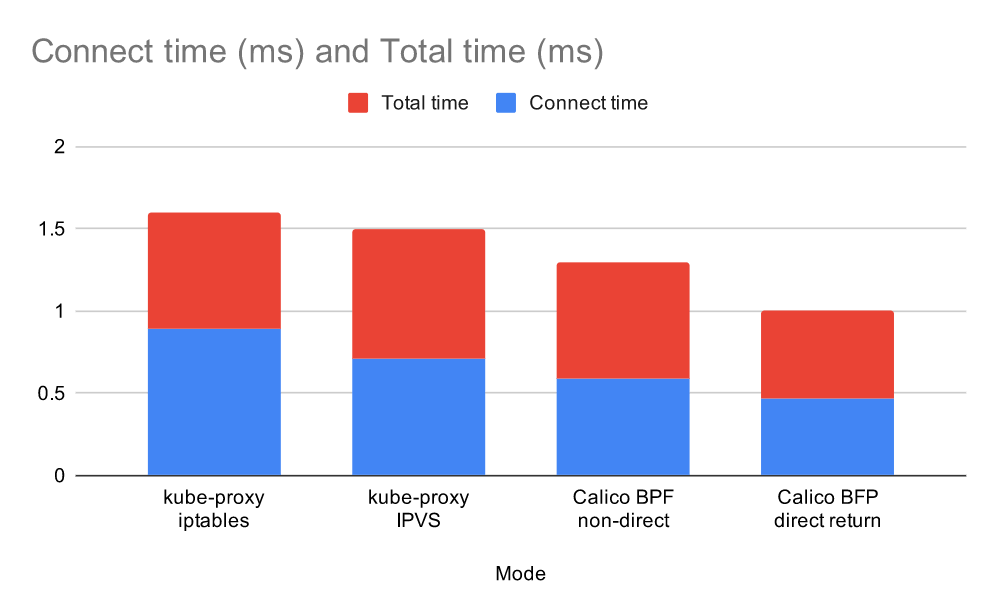
The BPF dataplane performs well and turning on direct return gives a further boost.
Efficient dataplane updates
When a service is updated, kube-proxy has to make updates to the iptables or IPVS state in the kernel. With eBPF, we are able to update the dataplane more efficiently.
The graph below shows whole node CPU usage during a test that
- starts with 5000 static services, each backed by 5 pods
- sleeps for 90s to get a baseline
- churns just one service for 100s
- sleeps for 90s
kube-proxy was configured with its default 30s max sync interval. All the dataplanes were configured with a 1s min sync interval.

As expected, with 5k services, you can see that kube-proxy in IPVS mode uses less CPU to keep the dataplane in sync than kube-proxy in iptables mode. (And the gap between the two would grow bigger if pushing even higher numbers of services or service endpoints.) In contrast, our new eBPF dataplane has an even more efficient control plane, using less CPU than kube-proxy in either mode, even at very large numbers of services.
What does “Tech Preview” mean?
Our goal with the upcoming “tech preview” release is to cover a broad set of Calico features. Enough to prove out the approach and get feedback from the community. However, as it is a tech preview it has not been through our usual level of testing and hardening, and there are gaps and limitations to be aware of:
- Most significantly, it is not ready for production!
- eBPF is a very fast moving area in the kernel. The tech preview requires kernel v5.3+ and has only been tested on Ubuntu 19.10.
- We haven’t implemented host endpoints or IPv6 support yet.
- The current implementation assumes a single host IP per node, so it’s unlikely to work with multi-homed set-ups.
- We haven’t tested performance with our IPIP and VXLAN encapsulation modes.
- The tech preview requires Calico IPAM (so it is not compatible with non-Calico CNIs).
- The implementation is currently limited to a few hundred policy rules per pod (though this should be more than plenty for most normal scenarios).
- MTU handling and ICMP error reporting are only partially implemented.
As a general point, there’s no free lunch, to get high performance, we bypass parts of the kernel’s packet processing logic, so you lose some of the flexibility of standard Linux networking. For example, if you want to add your own iptables rules, it’s likely they will be bypassed for pod traffic and won’t work as expected.
Conclusion
The Linux kernel’s standard networking pipeline will likely be a mainline choice for users and enterprises for many years to come, and Calico will continue to support it, providing excellent performance, scalability, and reliability. But for those ready to adopt newer kernel versions, Calico is ready to push the Linux kernel’s latest networking capabilities to the limit.
Whichever choice is right for you, you’ll get the same, easy to use, base networking, network policy and IP address management capabilities, that have made Calico the most trusted networking and network policy solution for mission-critical cloud-native applications, estimated to be powering more than one million nodes every day.
If you enjoyed this blog post then you might also like:
- Hands on with Calico’s eBPF data plane native service handling
- Free online training and workshops
- Learn about Calico Enterprise
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!


